Lambda Web Mapping: Part 2 - Building it.
I started work on the 09-09-20, 99% finished on the 10-10-20.
I’m just going to list in sections, the parts of the project as I build it, keeping any important notes along the way.
I’m generally approaching this problem from back to front. Starting with the data processing. Then I’ll build the Lambda and infrastructure, and then the javascript monstrosity. Hopefully, this will read like an exciting travel diary.
Building the Database.
This repo contains my data packs code. smap
There are two command-line tools. There will be another repo called smap_web which will contain the javascript bits, any API definitions that I build, and the Lambda function. Golang repositories are tricky and don’t really play well with having a bunch of other filetypes dropped in with them. So this is why there’s a split with smap and smap_web on github.
smap - Why two command-line tools?
In the previous iteration of this project. I used MySQL to load an in-file record into a database. DynamoDB doesn’t have ETL tools direct from AWS. Instead, there’s an SDK. Which means it’s up to you to figure out your load process. The intent of my CLI tools is that they will be easy to wrap in a bash script. I want to simply run the data packs through a transformation process and then load them to AWS.
The target for the CSV is an AWS DynamoDB which is a NoSQL DB (A giant HashMap). I intend to store the records in a structure where they can be fully self-describing. The first CLI tool I made was the csvtransform.go tool which parses an input CSV and then spits out JSON object.
The transformation program uses an exported data structure (record.go) that I created to allow it to integrate with the loading program.
The intent of the CSV transform step is to take a CSV file and for each row to try and fit it’s contents into this shape. Which is like loading 1 row of a CSV into a DB tuple as a JSON map. But in DynamoDB terms, thats loading one ‘item’ not tuple.
// Record. A struct used to create a JSON object representing a region ID and then a set of key value pairs of data.
type Record struct {
RegionID string `json:"RegionID"`
PartitionID string `json:"PartitionID"`
KVPairs map[string]float64 `json:"KVPairs"`
}
In real life looks like a big array of records like this..
[{
"RegionID": "1", #Aiming to be AWS SORT Key
"PartitionID": "G02", #Aiming to be AWS Partition Key
"KVPairs": {
"Average_household_size": 2.6,
"Average_num_psns_per_bedroom": 0.9,
........
........
"STE_CODE_2016": 1
}
}, {
"RegionID": "2",
"PartitionID": "G02",
"KVPairs": {
etc etc
Finally, I just dump that JSON text into a file in and output folder. And that’s the transform step done.
Of significant note: The RegionID and PartitionID fields. They are related to Partition and Sort keys on the DynamoDB. Knowing that the data comes in CSV files with a topic sequence, I’m using these topic code values as the partition key. This means that if the data ever grows past 10gig (it wont). Then it will get split into separate buckets for performance, based on the partition key. The G02 partition id in the above example will have 70K region id’s and so will all the other GN tables thus giving everything pretty similar lookup speed.
Importantly all of this is moot because I’m not going to hit the size where partition keys start getting used to physically separate data. However, you should have a read of a really good explanation from AWS. Funny note, I mixed these up, and fixing it was awful.
Choosing the Right DynamoDB Partition Key
The upload program
dbbuilder is the other CLI tool that handles a few tasks. At its core, it reads the array of Record objects and fits them into the AWS Golang SKD structs and then uploads them to DynamoDB. If the DB schemas don’t exist it can also build that. And there’s also flags to purge and or delete a DynamoDB table if needed.
It works well enough and everything was simple until I started using the AWS Golang SDK. And then Batch uploads to DynamoDB happened. (╯°□°)╯︵ ┻━┻. Cathartic Reddit thread about the AWS Golang SDK
Long story short but this function is all about filling up a batch input request with records. I have >56,000 of those for SA1 level data and the DB needs them in 25 record chunks. And that results in pretty gruesome code like this. Don’t judge, I’ll admit this may be a bad way of doing things but it was not easy to grok from the doco. The documentation has a bad habit of using examples where structs are coded as literals. This isn’t beginner friendly at all IMHO. Have a glance at the doco and sample code for the Golang SDK - DynamoDB - BatchGetItem you may disagree, but I think a more instructive example would be to build a struct, then place it in another, then so on until you had the completed structures to use.
func composeBatchInputs(recs *[]record.Record, name string)
*[]dynamodb.BatchWriteItemInput {
buckets := (len(*recs) / 25) + 1
arrayBatchRequest := make([]dynamodb.BatchWriteItemInput, buckets)
for i := 0; i < buckets; i++ {
wrArr := []*dynamodb.WriteRequest{}
stepValue := i * 25
for j := 0; j < 25; j++ {
if j+stepValue == len(*recs) {
//fmt.Println("Length of recs")
//fmt.Println(len(*recs))
break
}
av, err := dynamodbattribute.MarshalMap((*recs)[j+stepValue])
if err != nil {
pr := dynamodb.PutRequest{}
pr.SetItem(av)
wr := dynamodb.WriteRequest{}
wr.SetPutRequest(&pr)
wrArr = append(wrArr, &wr)
}
wrMap := make(map[string][]*dynamodb.WriteRequest, 1)
wrMap[name] = wrArr
arrayBatchRequest[i].SetRequestItems(wrMap)
}
return &arrayBatchRequest
}
Anyway, It works and as we learn when young…
Son: Dad why does the Sun rise in the east and set in the West?
Father: It works, don't touch it!
At least for the time being I’m not going to hack away too hard at this bit of the codebase. AWS looks like they have a V2 of the Golang SDK I’m sure it’ll get a bit of love.
I have to do some testing at the edges of the limits to make sure there are no offset errors and such but things look good so far.
One day Later
In anticipation of developing the front end code and lambda function for the API gateway I needed to create the database and put data in it.
And that all just worked!
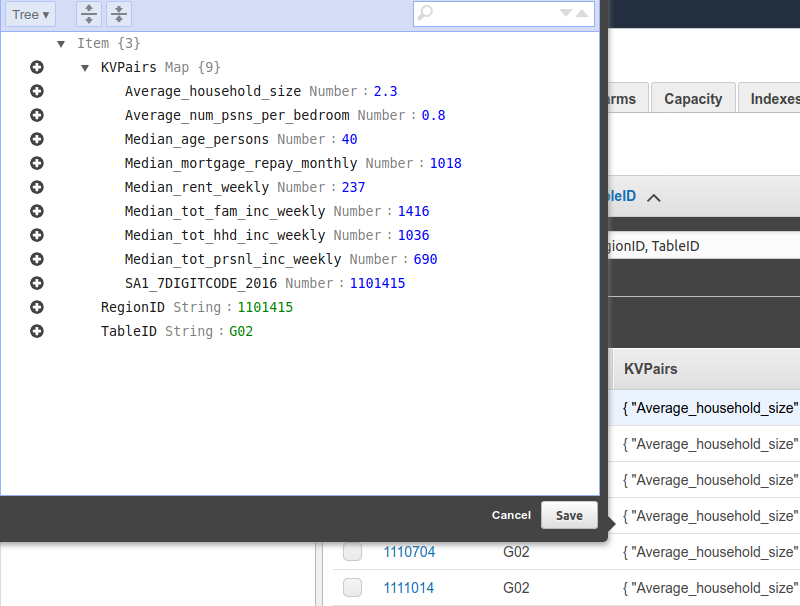
And everything got uploaded!
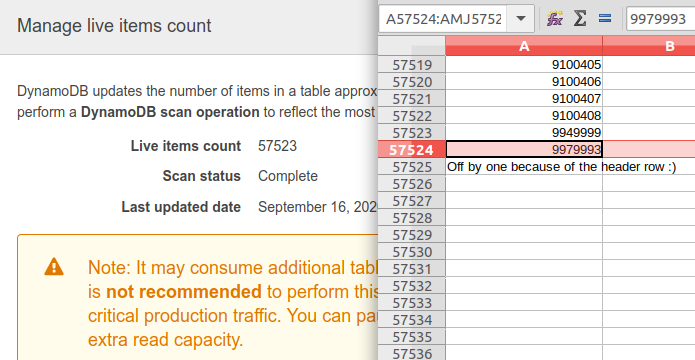
I’m pretty happy that went so well.
Writing the Lambda function
This little lambda function should be simple.
–Gabe Sargeant
The Lambda function did not turn out simple at all
–The narrator
Checkout the smap_web / lambda folder for the final version.
Basic stuff I need to do with this lambda:
- Get a session.
- Get a DynamoDB connection
- Connect to the DB table with the data packs
- Get the content matching the RegionID and PartitionID, ie key and partition.
- Return all that.
Extra points.
- Unit test the lambda function. ie mock out DynamoDB and the AWS API and have that code the final deployable version.
Extra Extra points
- Optimise all of the response code to lighten the burden when the response object is handed back to the javascript client.
- Make a unit tests!
Steps 1 –> 5 were pretty easy. Obviously, API Gateway isn’t in the mix yet but the general mechanics of the lambda are pretty much the same. I followed this AWS guide on Golang Lambda functions as a start, and that was actually pretty simple. At this point, the lambda function was ‘working’. I deployed it up to AWS and gave it a go.
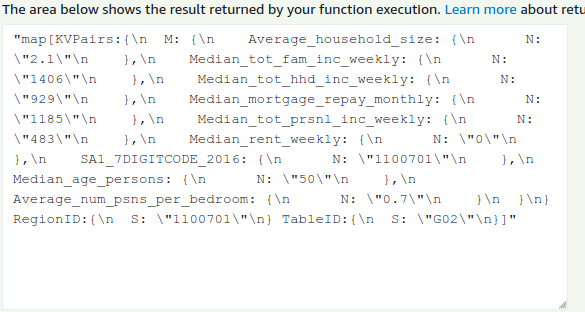
Step 6
This was really interesting. In my past life, I’ve shied away from the use of interfaces for testing and mocking, favoring a constructor-based dependency injection via some top-level factories and used testing frameworks such as Java’s Mockito. I’ve always found this style of approach to be very testable and readable. However, because the lambda function has only 7 allowable method signatures there needs to be another way around that. This turns out to be dependency injection using pointer receivers and the heavy use of AWS SKD interface types.
This AWS events webinar was so good I actually liked the video and subscribed to the channel. Youtube: Unit Testing your AWS Lambda Functions in Go
Step 7
I’m just going to be kicking the client in the teeth :D
Hello JSON my old friend.
Not only because the AWS Golang SDK is just so ;gah’, Im going to grab a whole tuple from the db and get the front end to clean it up. ie. I’m going to get the Lambda function to send back an array of tuples and that’s it. The Javascript will be doing the building of the data table. It’s not terrible but also not great. I’ll totally circle back and refactor maybe.
DynamoDB supports a query syntax to enable pulling down sub results. What I’m doing right now is akin to select * from table; I’m not sure if the added overhead of naming columns and the work that involves is easier done, both in code terms and mental complexity in either the DB layer the Lambda Layer or the Front end.
Considering I’ll be doing the work. I’ll start with the front end and then if that’s terrible I’ll try some stuff.
Step 8
Writing the unit test was pretty straight forward due to the pointer receiver dependency injection. AWS supply their whole interface in the dynamobdiface stub package. You just include that interface as your injected ‘DB’ and then you just need to implement the desired methods for your tests.
In the git repo I have a somewhat simple test that does enough to show the happy path of the test. At the time of writing this I haven’t quite figured out what I’ll do with errors that pop up during lambda execution. I’m thinking of expanding the response record type to include optional warnings and errors string.
Whilst I ponder on that and move forward with building the API Gateway components. One final thing to note, the API gateway request and response objects that are implemented in the lambda events package, events.APIGatewayProxyRequest & Response, means that I’ll be sending a lot of JSON in the Body field of the object. It’s an extra marshalling and unmarshalling step that has to happen with the json. It’s not really an issue just something I have to deal with.
Step 9
Consider what the hell I’m going to do about Metadata. TODO
API Gateway
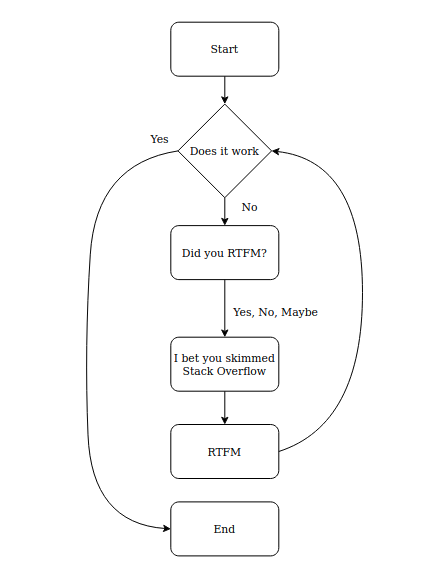
Setting up the API Gateway was hard and then it was really easy. It got easy once I stopped messing about with AWS and started reading about AWS. Who knew!
It can be summarized by this flow chart which oddly looks like a finite state machine.
I lost about ~5 hours to a really stupid mistake of not setting an HTTP response code in the lambda events.APIGatewayProxyResponse struct. It turns out that HTTP response codes are pretty important for a HTTP API. As is clearly described in the first sentences of the doco about version 1.0. ಠ ∩ ಠ. Consequently, API Gateway will not send a response if a HTTP code isn’t set. Why did I miss this? Two reasons. I really was skimming stack overflow trying to grok the answer to why my API wasn’t just working. And the Events package has two versions of the APIGatewayProxyResponse struct which both share most the same fields. As I didn’t have a solid grasp of what I was doing I picked the first one and didn’t bother with a response code. This is where some code comments on the struct type would have helped AWS.
In addition to this confusion, in the API Gateway when you configure the endpoint for the lambda integration you have to select a Payload Format Version. That needs to match up to your code. If it doesn’t, it seems the API gateway just looks at the struct and makes a choice on what’s best. So even when I toggled that to version 2.0. It was the seeing version 1.0 struct and throwing an error instead of responding in absence of the response code, which is the default behavior of version 2.0.
After printing almost everything to the CloudWatch logs to see my Lambda was working I started looking more and more at the documentation. Notably, the one thing that probably held me back a little was that all the tutorial code is javascript for the API Gateway. Having built everything in Golang, and also being fairly new to it I didn’t really have the eyes to spot this error.
Anyway, it works!
Stuff still TODO:
- I need to consider the placement of the API into this domain with DNS. I can just use the default URL, but this may present a problem for CORs and the javascript in the mapping framework.
- Rate Limits for the API, just in case.
- Figure out and deal with all the awful CORs issues related to 1.
One day later
I really wanted was to lay the API gateway across my domain like so:
my domain.com/lambdamapping.html <== the hugo / static parts of the site
my domain.com/app/smap <== this is the api gateway stage
The API Gateway root is /app and the POST request URLs at /smap/getregions. It would have fit better and been more cosmetically pleasing to integrate the site and gateway this way to me. I can’t be called out on this desire. If you consider all the crap I went through to understand the irrational desire for pretty URLs on websites these days
As you can expect Amazon has had other designs in mind. Probably because doing this day and day out, they could easily anticipate that overlaying two sets of URL schemes on top of each other will lead to bad times.
So I’m not going to fight with it. To make up some lost time, my api just follows the usual stock patterns.
Speaking of saving extra time. I started to read up and implement the new route for API Gateway. All that was required was creating a new Route 53 alias certificate with the api prefix and mapping that the to my API Gateway.
Then I realized that I built this site with HTTPs and with an SSL certificate that didn’t use a prefix wildcard. \(`0´)/. No time was saved. Not one time at all.
I started out knowing I had to change out certificates for my CloudFront distribution. Which is actually pretty easy. It just meant going into the AWS Certificate Manager and trying to delete the existing cert. Which doesn’t work? You have to remove dependencies on certificates before you can remove the certificate.
So I went and requested a new certificate and whilst that was provisioning I attempted to remove the bad one from CloudFront Distributions it was associated with. Then it should have been simply just updating CloudFront with the new certificate.
That’s about the time I noticed the spelling mistake I made…in my own name sigh. I’m putting that one down to a rough day at work. But needless to say, I got to try this process a few more times.
One thing does strike me about AWS. All of their products are reasonably good. They give you access to a lot of power. But the console UI is not amazing, it’s getting better but still somewhat lacking. Case in point. I easily spent ~10 minutes trying to understand why a new SSL cert wasn’t visible on my CloudFront distribution’s list of certificates. And this turned out to be because I had an existing certificate selected that needed to be deleted (via the backspace key) to allow the drop-down of other certificates to present itself. I know the default response would be to use the SKD or CLI but I have rather a small operation going on here.
Anyway, all of that was done and then it still didn’t work. This picture explains my mistake.
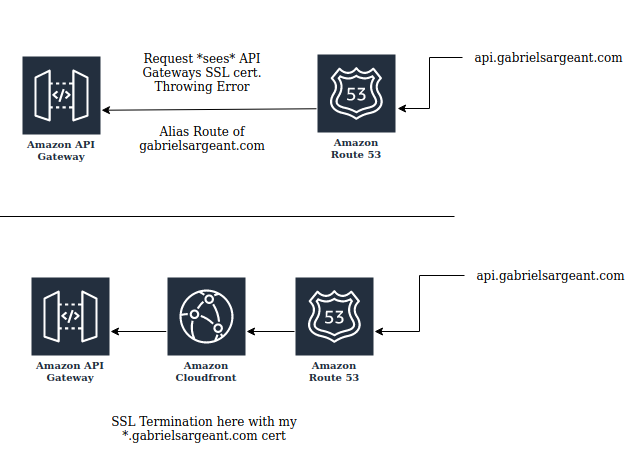
I needed to the route to go api.gabrielsargeant.com to CloudFront to terminate SSL with my certificate that has the *.gabrielsargeant.com name so that CloudFront can handle communications between API Gateway and itself before rewrapping the request with my HTTPs cert.
As always when working with SSL, Certificates, and DNS. Never Again! at least for a little while.
I am yet to deal with CORS, hopefully, it’s very simple considering I now have the API with the same origin!
Metadata - Lambda Function revisited.
In some of the more detailed parts of the Census Data Packs the short column header names can get a little tough to understand.
For Example
The Short header: A15_24_SOLSE_PinE_NS_06_10
means
“Aged 15 24 YEARS Speaks other language and speaks English Proficiency in English not stated 2006 2010”
ABS provides conversion information in a few metadata files with the Data Packs. I needed to incorporate this information into the application. I had a few ideas on doing this.
Firstly, I considered rewriting my CSVTransformer CLI tool too accept two data files as input, I’d need to do something to attach the metadata into a special record for each partition. In broad strokes, the DynamoDB data has the primary key structure of Sort Key, Region ID: PartitionKey: PartitionID I was thinking about having a special record for each partition that was Sort Key, PartitionID: PartitionID: PartitionID This would have allowed me one item per partition in the dynamoDB that was non-statistical data. I liked this option, however I think it would mean that all of the numeric data would have to be stored as String and not Numbers to make the KVPairs field work correctly for this edge case.
The other idea I had was to put the metadata information into a JSON file and serve it with the webpage from S3. I wasn’t thrilled about the idea of doing this though. The metadata is about 800Kb. One of the reasons I have a static site is to leverage the small page sizes and quick loads. The mapping and visualization parts of this project will have their own heft to them so I was keen to look for a solution that minimized initial page loads.
I could have easily added another DynamoDB table. But for 800Kb of information, It probably wasn’t worth the drama of it all. And I briefly considered splitting up the metadata file but that could get messy with about 100 partitions in play.
Instead, I opted for a wonderfully lazy approach, that’s both hacky and not.
I made about 100 Golang Map Literal objects which map to the CSV Tables / PartitionID’s. And then I put all of those in a map of maps as source code. This really gets the line count up for my lambda function but it doesn’t affect much else.
The logic in the Lambda function is to read the PartitionID from a request. Get the Metadata from the MetadataMapOfMaps Object and then attach that to the response object.
The result in the transmitted MapResponse is a JSON metadata map which gives out the human-friendly names for the data keys.
This looks somewhat bad from a code perspective, but it’s not. It’s a simple solution. If I was building a more generic data store. I would probably roll out a metadata table in Dynamo.
This was one of those small foresight issues where I’d preference keeping up the momentum of moving towards a solution, rather than getting tripped up in a whirlpool of rewrites seeking out perfection.
Importantly it works!
// MapDataResponse - The Golang object for my response object
type MapDataResponse struct {
Errors []string `json:"Errors,omitempty"`
MapData []MapData `json:"MapData"`
Metadata map[string]string `json:"Metadata"`
}
//And a sample output from a single area request.
{
"MapData": [{
"RegionID": "1101118",
"PartitionID": "G02",
"KVPairs": {
"Average_household_size": 2.6,
"Average_num_psns_per_bedroom": 0.9,
"Median_age_persons": 44,
"Median_mortgage_repay_monthly": 1578,
"Median_rent_weekly": 220,
"Median_tot_fam_inc_weekly": 1792,
"Median_tot_hhd_inc_weekly": 1645,
"Median_tot_prsnl_inc_weekly": 803,
"SA1_7DIGITCODE_2016": 1101118
}
}],
"Metadata": {
"Average_household_size": "Average household size",
"Average_num_psns_per_bedroom": "Average number of Persons per bedroom",
"Median_age_persons": "Median age of persons",
"Median_mortgage_repay_monthly": "Median mortgage repayment monthly",
"Median_rent_weekly": "Median rent weekly",
"Median_tot_fam_inc_weekly": "Median total family income weekly",
"Median_tot_hhd_inc_weekly": "Median total household income weekly",
"Median_tot_prsnl_inc_weekly": "Median total personal income weekly"
}
}
Thoughts on optimizing the lambda function The current lambda function has the following request logic.
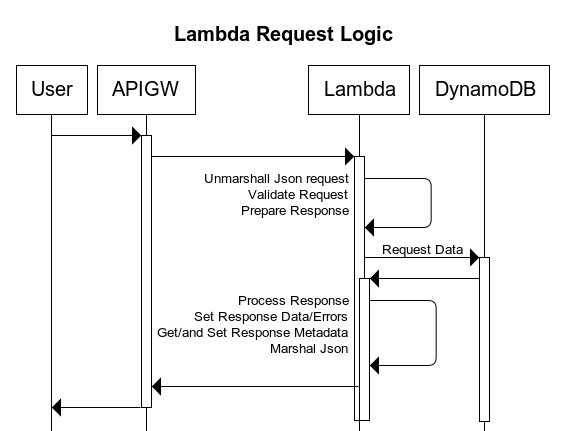
If the performance from dynamoDB is and issue and I’m chasing milliseconds in Lambda execution speed then there’s a few things I can do to making things happen faster.
I can play around with the initialization of the AWS session using an Init block in the Golang code. using global state. This may help.
One other thing I can do is use go-routines and channels to do as much work whilst the DB result is getting fetched. It may be something, it may be nothing to set that last metadata map. As opposed to the speed of a DB request. But if I do both at the same time I gain a little speed on the front end back.
Interestingly, my testing so far has focused mostly around getting either 1 object, or 100 objects. Aside from size in response the felt time of a non-cold start request seems to be about the same. But I’ll probably refactor the code to use channels because it looks fun.
CORS - 눈_눈 - I don’t like CORS
CORS was about as complex as I expected. So that means I understand it, but I’ll be second guessing myself forever.
How I got CORs working between API Gateway and the S3 site.
Firstly, I changed no settings with the S3 buckets or their CORS policies.
In the API Gateway doco about CORS and HTTP APIs, it explains that you have the option to set COR’s headers in your lambda function or integrating application. Or, you can take the easy route and set them at the API Gateway. This will have API Gateway dump any headers from the application and just uses what’s set in the gateway.
I went with the API Gateway override option to avoid having to write header information into the Lambda function.
I Allow:
"Access-Control-Allow-Origin" : "https://www.gabrielsargeant.com"
"Access-Control-Allow-Methods" : "POST, OPTIONS"
This means when a request comes from S3, API Gateway will accept it, do the work, and respond.
Everything was setup there, so I wrote a quick and dirty web page to make a POST ajax request for data from the API. I put the test application into the static directory of this Hugo site and deployed the updated changes to the website.
Then it didn’t work. And I spent a few hours with this!
Cross-Origin Request Blocked:
The Same Origin Policy disallows reading the remote resource at https://api.gabrielsargeant.com/app/smap/getregions.
(Reason: CORS header ‘Access-Control-Allow-Origin’ missing).
The issue ending up being CloudFront. I have 3 CloudFront Distributions. The first is this website, The second is the bare redirect to this website, the third is API Gateway. All of them strip headers from being sent by the server.
This is to maximize caching behavior. In order to enable requests from the website origin to the api gateway, I configured the CloudFront Distribution for API Gateway to use the AWS Managed-CORS-S3Origin CORs policy.
This allows CloudFront to expose the above headers to requesting applications.
It wasn’t too hard setting this up, once I understood CloudFront was the issue. CloudFront Dev guide - Managed CORS policies
Once this was done, things worked. Small win for the night.
The land of frontend….
I have the following frontend tasks TODO:
- Turn the map response json into a html table.
- Turn the map response json into a map and do all that fancy rendering stuff etc.
- Style the monstrosity.
- Use reasonably sensible javascript. This is actually a really hard step. The market fragmentation in the JS language world has created so many extra features, like all the functional style syntax. This means that anything you do will generates opinions. I’ll struggle through.
- Extra hard, Mobile friendly!
I may not do 5. It could be too much.
Finding a reasonably irritating mistake in my data structures If you look at the sample response from the above section on the Lambda Metadata. There’s an issue. They KVParis object has the following entry in it.
"SA1_7DIGITCODE_2016": 1101118
This isn’t present in the metadata object. This is because of how I’m relying on the ASGS and region codes to be unique, allowing me store all data and hierarchies in one big table.
This only shows up as an issue when I try and write out a table in Javascript.
I iterate through the metadata object to create the <hr></hr> header tags. I want to use the human friendly name and the machine name as the column/cell id. This works. However, the problem is there’s an offset error. There isn’t a metadata entry for the last row, which is the SA1_7DIGITCODE_2016 value. I think I should have included an extra attribute in the blob to also record the geography level of the data.
This issue stems from the cell descriptors file I used as the source of the metadata. And the KVPairs in the MapData array are direct from the CSV. The RegionID is what I put in the first column. It’s just a copy of that other region identity.
Right now, I’ve fixed this with a hacky solution, but it makes me think that I should potentially not include the region code in the table data KVPairs object. Which means rewriting the csv_transformer go program. I think I can work around it. Probably something to sleep on as there could be a way around this issue that I haven’t though of yet.

Just a screen shot of a file I’m using to build up the feature before starting to integrate it into the main front end code.
Tables Day 2
I’m not fully finished with that metadata issue. I do want to finish this project as a working first pass before going back to refactor it.
Now, onto the front end.
As I expected, this isn’t going to be mobile friendly at all. Which I’m fine with. No one doing actual GIS style work does ‘apps’. Unless they’re just a worker drone out collecting data. We have desktops for a reason. And in my case, that’s a perfect reason I can use as shelter to not worry about mobiles. :D
Before doing any of the mapping bits and the wiring together of things, there’s placement. As I discussed in my previous retrospective, I wanted to try and achieve just one page where you could do everything. I’ve got a working prototype of this.
Please forgive the garish colors. But I’m using the Z-index plane to overlay each of those pages and it’s easier to track state visually for me this way.

Things to think about:
I’ve got to cleanup the data table and think some more about limits. In the gif there’s 100 data responses that get dumped into a table. With some of the larger areas im going to have issues with horizontal scroll.
Also with thematic mapping the number of selections may present an issue with render speed. In fact I know it will. So I may be dialing the selection limit back to around 20-40. Plus side of that is I save money.
Otherwise I’ll probably start with the maps in a day or two. I just want to build some of this boilerplate logic and setup the page well so when the complex work starts with the map, I don’t have a code base that looks like dropped spaghetti.
Delays
Metadata, You suck.
In addition to metadata sucking, so does the non-ASGS regions. Australia is a somewhat progressive country. Lets do it, lets get rid of post codes and just use the ASGS.
In another late breaking mistake. The ASGS uses all numeric region identifiers. The non ASGS structures use alphanumeric codes. My DynamoDB Table doesn’t really gel well with this and needs to be changed so it’s schema supports RegionID is a string. FML. This is a slightly big change.
Affecting,
- The CSVTransformer,
- The Upload,
- The Lambda,
- and the front end.
From my perspective, the best way to solve the numeric and non-numeric regionID issues is to take a moment and refactor everything to fix all the other metadata issues I found previously.
Fixing the metadata issue
Tip of the hat to golang, the changes turned out to be only a few slice alterations.
When I consume a row of CSV I don’t include the first element of the CSV row slice and that clips out the regionID which may have included A-z characters. This identifier is then placed in the MapResponseObject along with the GeoLevel which I extract from the filename. Problem solved.
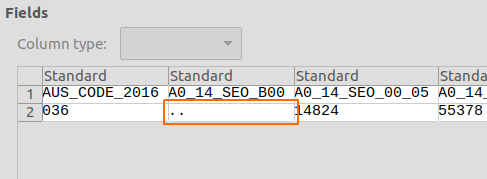
The next issue I hit was the presence of characters like .. these represent suppressed numbers. Ie, counts of people where it’s likely the response numbers are so low that there’s a possibility of disclosure. I need these to be a number, and not a set of dots to be able to ingest them.
Those .. actually do convey information. So they need to be kept. For simplicity, I’m converting them to -1. And I’ll annotate as such on the front end.
Load Scripts
This handy tree command outputs all the census data pack filenames into a folder. A little search and replace to build up the scripts and the bulk csvtransform script was written.
tree -ifR > dataloadscript.sh
The Lots of Data Problem
After I made the changes to the csvtransform program I ran it against all 1870 csv’s that make up the full Census data packs. This outputted about 30 Gig of json. That size is pretty much what I expected when I de-normalized the schema.
However, I don’t really want to have that much data in AWS for an App I may use infrequently. So I’ve been looking at the metadata catalog for table names that do and don’t interest me.
I’m going to exclude everything but the following tables in the app.
- G01 Selected Person Characteristics by Sex
- G02 Selected Medians and Averages
- G04 Age by Sex
- G05 Registered Marital Status by Age by Sex
- G07 Indigenous Status by Age by Sex
- G08 Ancestry by Country of Birth of Parents
- G25 Family Composition
- G27 Family Blending
- G28 Total Family Income (Weekly) by Family Composition
- G29 Total Household Income (Weekly) by Household Composition
- G30 Number of Motor Vehicles by Dwellings
- G31 Household Composition by Number of Persons Usually Resident
- G59 Method of Travel to Work by Sex
The reasons these got included and others didn’t is twofold.
- Census Data is really granular. If you look at G59, the Table is Method of Travel by Sex. That ‘By Sex’ means that there’s a cross-product happening between two categories. Which results in massive data files. Hence why I excluded categories like
- G17 Total Personal Income (Weekly) by Age by Sex
The amount of information in those files is too much for a webpage to coherently display. There’s 110 age categories by a lot of income brackets. And eventually what you’d want to do is reclassify these categories into new rolled up data, Such as 5 year groups. Which is a perfect reason to load the data into a database with cheap SQL features. (Next year maybe)
- Some of the table data didn’t spark joy in my heart. And it would probably not be hard or impossible to visualize with meaning in a web browser.
And lastly, I’m not going to include SA1 level data. Only nerds know what their SA1 is and most people understand regions they can related to such as Post Codes and Suburbs generally relating to SA2 level data. Excluding SA1 data also helps save a bit of space. Than the above selection is about 2GB of data with SA1 and 800MB without. It’s easier exclude them.
Later that same day
All the geographies from AUS–> SA2 are loaded for my above-selected topics. About 788MB of JSON in the end, totalling 333186 items in DynamoDB. It took about ~20 minutes to load it all up over my bad internet.
Nothing too dramatic happened in the load process. I altered the Lambda to respond with the new GeoLevel attribute and that’s about that.
I look forward to my next AWS Bill summary of activity to see if there’s any crazy (>$1) expensive charges. Everything I read and calculated says it should only cost about 50 cents to do the load, and then regular request activity shouldn’t be much.
I did run a live count scan on the table. So that may cost a bit (< $1) with 800MB of data. 800MB == 800000KB, 800000kb / 4kb unit cost = 200000 units. AWS Read Cost: $0.285 per million reads (ap-southeast-2/Sydney). I made 333186 reads. If I round up for simplicity 500K, 0.15 Cents USD. Roughly 20 Cents AUD.
I only need to pay that price once. As of right now, the DB is done!
Now back to the front end.
The next morning
It cost $1.75 AUD. I made a few script errors and my internet dropped out. So I reran it, twice, doubling the charge :|
Lambda edge case, G04 Age by Sex.
I have a motto about software processes.
Eliminate conditions. The path through good software should be like walking down a road with only one destination - Gabriel Sargeant
And keeping in tradition with that. I’m not including the G04A and B tables. Age by sex is too specific and too out of date for it to be useful or interesting and the G01 tables features the rolled-up counts in 5 year groups.
This also avoids a bunch of join logic. Either at the base csv layer resulting in a new upload of a joined A and B table. Or a join at the Lambda layer with double requests against the DynamoDB.
Side Mission
Deleting the already loaded data for G04A and B
I really want to write another whinging paragraph about the golang DynamoDB SDK. But, I won’t.
I had already loaded the G04A and B tables to DynamoDB. I wanted to remove them for cleanliness.
With DynamoDB, to do a Batch Delete you need to supply an Attribute pair of Hash and Sort keys in the same batch request format as above. I used the dbbuilder and chopped it up to do this. It was actually pretty simple. I just reread my input JSON files and then created a DeleteRecord struct that only had the Region and Partition ID fields.
So from there I just built a few batch write requests of DeleteRecord and, job done.
Back to the front end
Progress is a little slower towards the terminal ends of the project.
But things so far are going well. I’ve got topics, data returning on the webpage, a map that is selectable. All the parts dealing with getting data work.
Here’s where I’m at so far.
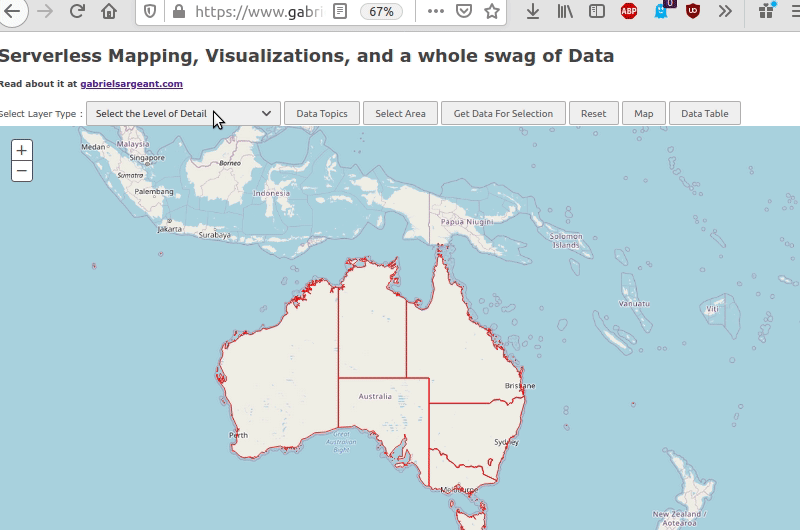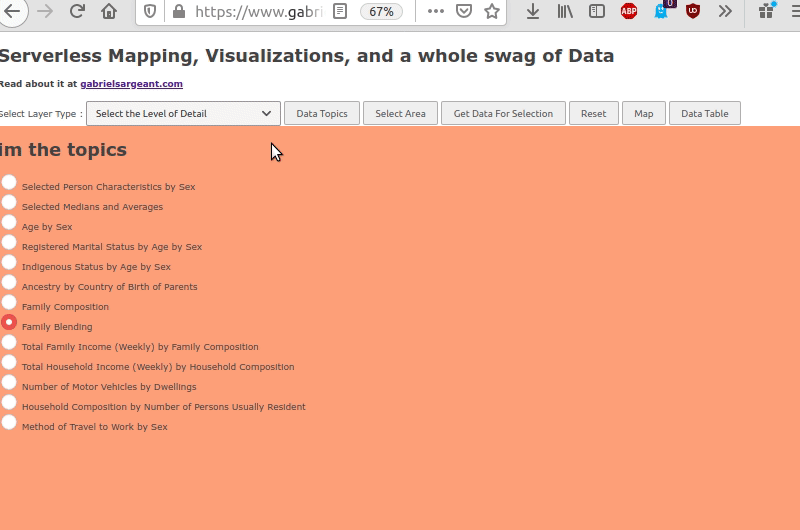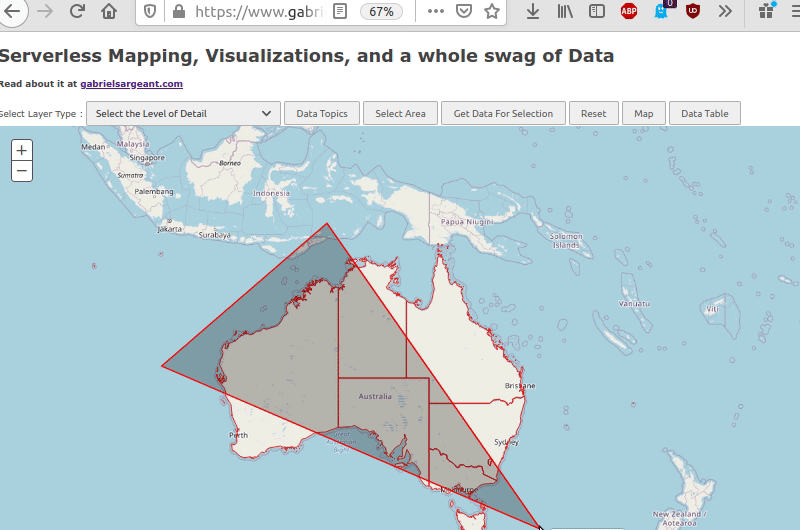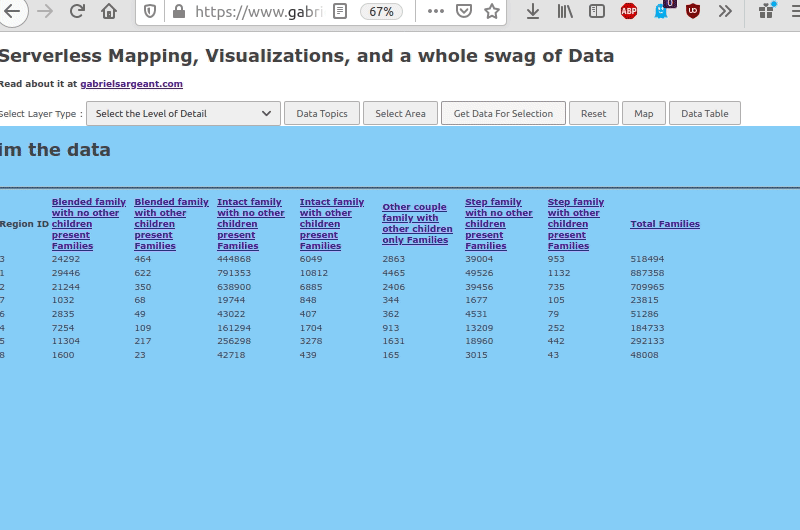
Optimizing javascript in an attempt to be friendly to everyone’s bandwidth
ArcGIS API for JavaScript Web Optimizer
This is a really good idea. However I’m not going to do it.
Partly because I’m lazy and other partly? :) because I won’t use this demo much once I’m done. The web optimizer works when you’re going to serve the cut down files yourself. in theory, I could do this and Cloudfront would deliver them from its CDN. That would be fast-ish. However, there’d always be that first time user experience that’d be a little slow on a cold cache. And it’s realistic and likely there wouldn’t be a second user on the site in time for that cached resource to get there even quicker. So the felt experience would just be what it is. I don’t see a ton of benefit from doing it. Though I have done it in the past.
Also I’m laying a lot of features on top of each other. The minified version just may not be that much smaller in the end.
Either way, this is the toolkit if the need arises.
Look and Feel
The map looks good! Everything else has the usual utilitarian shine. I’m starting to be happy with it.
Metadata REDUX! - Lambda Function revisited.
This was fun and easy. I already have a lot working on the site. The requests are stable. All the logic needs a shake out but otherwise it’s in a good spot. The only issue, My data tables look like this.
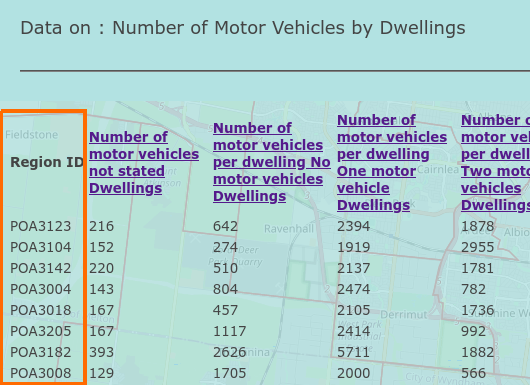
There are lookup tables that map those region numbers to actual values. Ooops. That should have been in the dbbuilder tool. Anyway, I used the same trick as before. This time it’s not as messy. But it is big. I totally know that I could fix this another way. But I’m just not ready to spend $4 re-uploading the changes to the DB.
So, the fix is a giant map which I put in the lambda function in a non breaking way. Not the worst outcome.
I’ll incorporate the change into the frontend in a day. Otherwise, things are speeding along. And for now, this issue goes onto the refactoring pile of problems.
Finishing off the front end.
So, I gave in an used jQuery. I’ll have a lot to refactor. But, I have a working project.
Thanks to my fat data model, I can just have a drop down for different data items on the visualization page. This works smashingly fast in practice because there’s no calls past the point where you see the data table. And that usually tops out at ~1 second max.
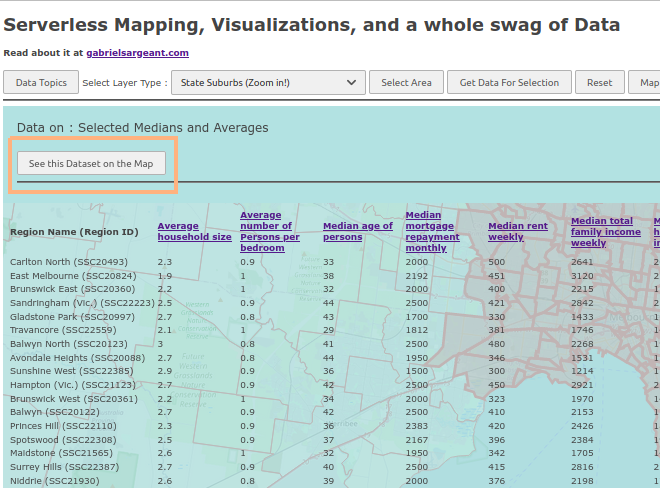
An example of the quick visualization from a small selection of inner melbourne.
please forgive the black side bar
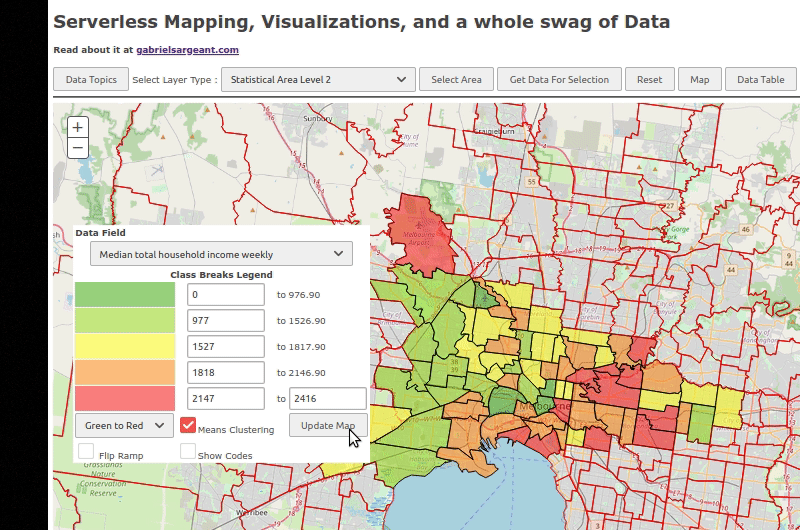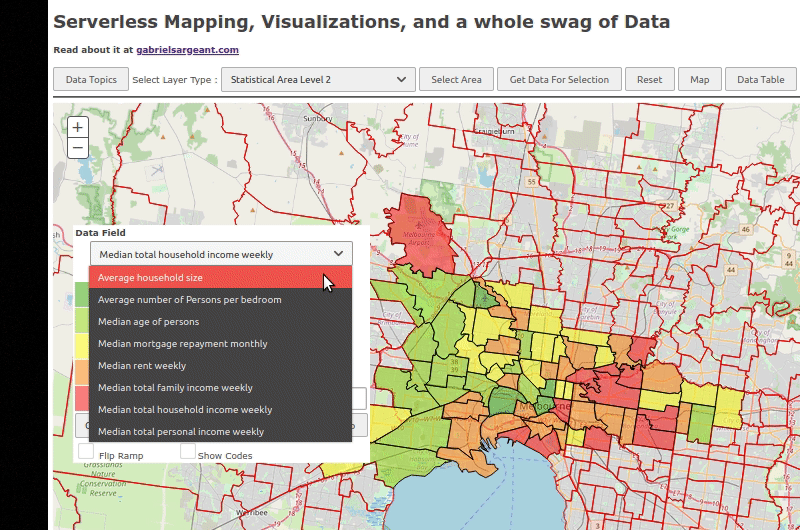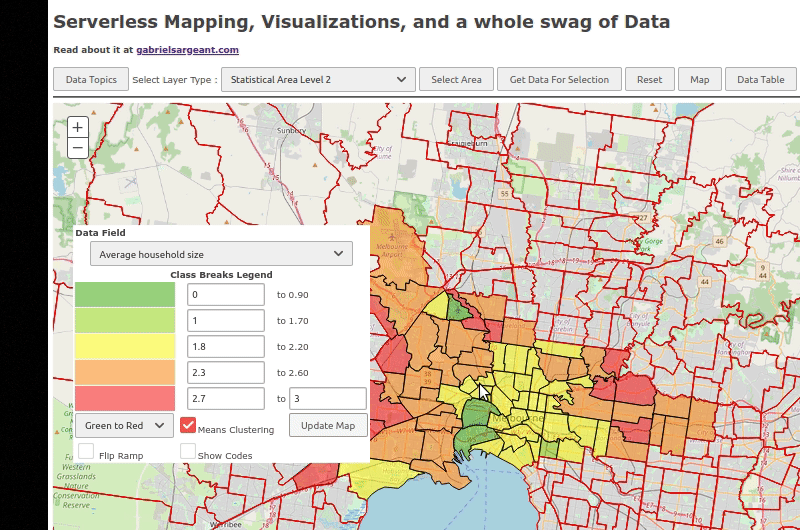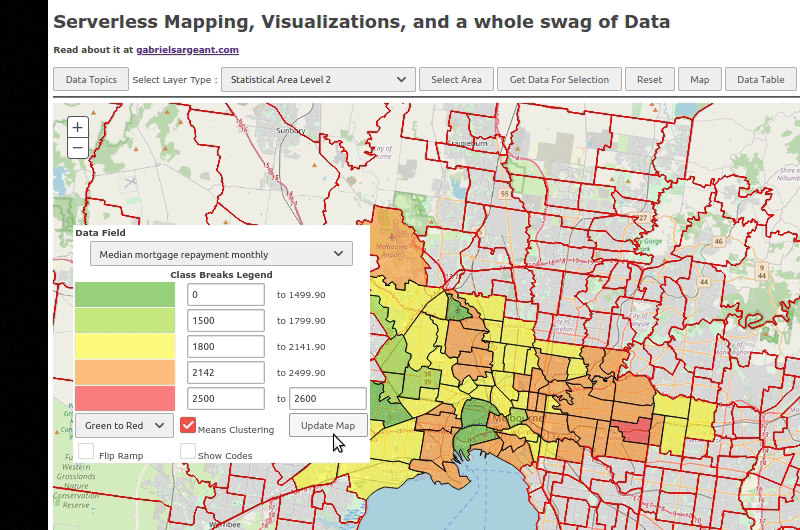
I have to set a few events to fire once the features are all downloaded and rendered. Other than that. Everything should be good.
I’m close to ending this death march.
Last few bugs.
In 2016 Australia had 9 State level areas. ‘Other Territories’ is the 9th. Moving down the ASGS it had, 107 SA4’s, 358 SA3’s, and 2310 SA2 regions. In both the front end and Lambda function I have a limit on 100 regions. This creates a UX bug with the Select Areas button.
The UX issues is that most users will drill down to show all the suburbs in Melbourne. If they try and get the data they will only get ~100 of those regions, and when they try and visualize that it will come up as a spotty image. Some of the regions will not be shown as they were clipped out of the request. In the image below the blue box is the original request area.
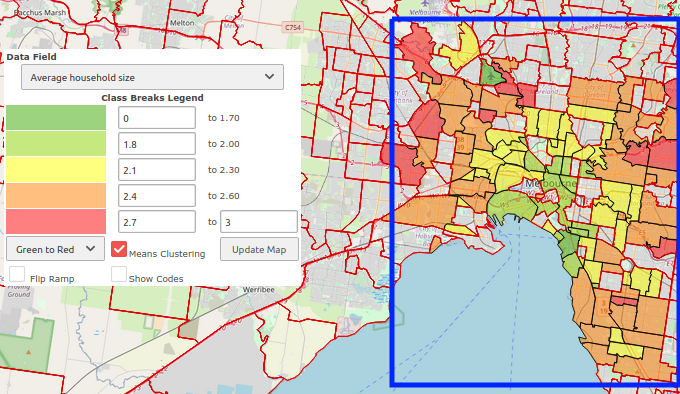
I’m keeping my limits. However, the ASGS isn’t randomly assigned numbers, there’s a sort of an order, and a slight relationship between close region numbers being also close physically to each other.
I now sort the requests by RegionID and then take the top 100 of that sorted list. I alert the user to the issue but still return the somewhat patchy response. As the owner, I am happy with this quality of service ¯\(ツ)/¯
It is possible to just lift the lid on limits, but this is all happening in a web browser. Something will break. This mostly becomes an issue at the SA2, Post Code, and Suburb Levels. Everywhere else, things are pretty sensible.
I’m still working out a few small bugs, mostly around the info templates that pop up when you click on the render. But other than that.
☞(゚ヮ゚)☜ I’m DONE ☞(゚ヮ゚)☜
This link is to the 99% finished site.
Serverless Mapping, Visualizations, and a whole swag of Data
In a day or two, I’ll write up a retro and some thoughts.