Graphs and the ASGS: Part 2
Before you read this, read what came before this. Graphs and the ASGS Part 1.
So… I got slightly distracted by the 2020 election. Who didn’t!. I think I watched like 96 hours of CNN. I won’t be doing that again for ~4 years. This was a super helpful distraction because this little jaunt into the ASGS has turned into a tiny bit of a death march. Anyway, I think I have a way forward.
General Approach.
I’m going to build two graphs. Two trees that I will join on their shared mesh blocks to construct one big graph.
Everything has a trunk at the Australia level, but diverge forming the ASGS, and Non-ASGS regions. Joining back at the leaves.
I need to create a process to walk the graph and build objects that show those pathways between each of the non-ASGS to ASGS.
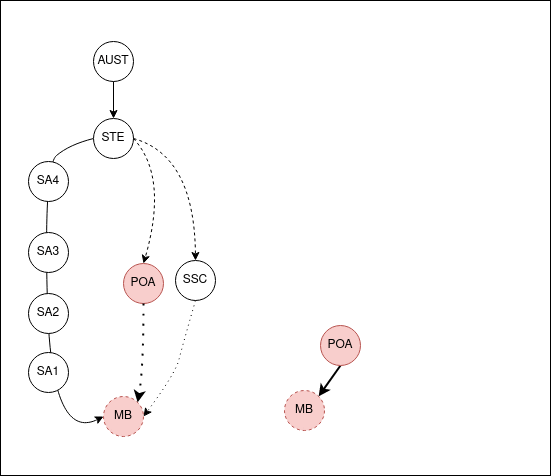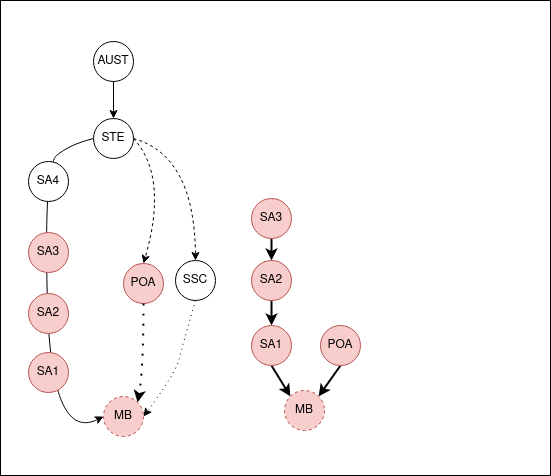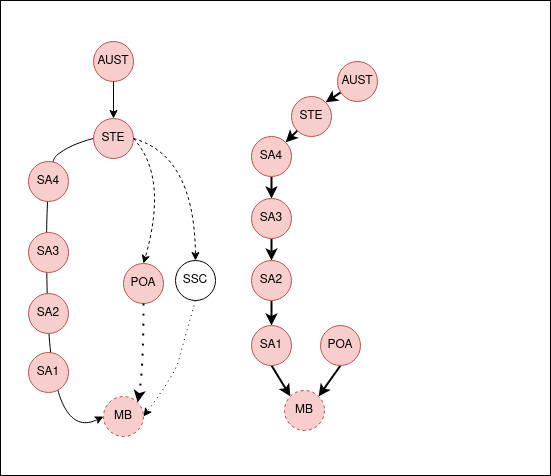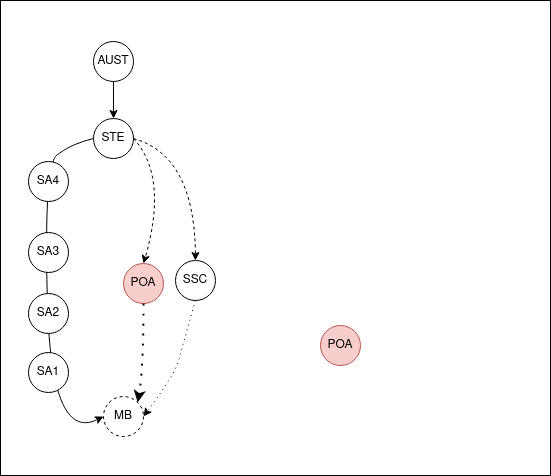
The POA and SSC areas are roughly like SA2 in size, both in population and physical space. Though in Australia, you can find an example that breaks every rule. Because of this general similarity, I’m going to omit the Mesh Block and SA1 levels. Rather, I’d like to abstract them into SA2’s as references that show the chain.
A few days later - my thoughts
I usually write this stuff late at night and also think about the problems fairly late. And that’s the reason why I totally blanked on the fact that the child regions for the State of NSW is everything in NSW. And that’s a really dumb thing to try and capture in a single object. In that above GIF the bottom-up search works because you’re going up. But if you search down on the ASGS side, because there’s nesting, you end up with a ton of objects.
I think I have rediscovered the reason for pointers and databases. Sigh.
Revised plan
I will make individual nodes that know their parent and their direct child but nothing beyond those direct relationships. I’ll spend the $5 bucks and put it all in DynamoDB, and wrap a lambda function onto it to expose another endpoint on API Gateway.
Now to ponder the indexes…
I legit hate this project now… The grim death march begins.
Ok, so I’ve been hard at work putting 400K objects into DynamoDB.
My old foe, the AWS DynamoDB Golang SDK has caused many issues. Most, actually all of them were my fault. However pointers…
The API will be something like: /asgs/getRegions?code&code&code etc. This time I’m going to use GET, as opposed to *POST requests. Yay, a friend of the cache. (•̀ᴗ•́)و
Doing something fun with javascript to interact with it.
Enter stage left: Sigma JS.. An oddly not HTTPs site. :/ OR Data-Drive Documents, d3.js
I’m going to do something with one of these… Not sure what yet. But I’ll figure it out.
I was considering doing something with Graphvis, I still may, however the Golang interactions with the Graphviz engine looks too complex for a humble Lambda. And it’d be a lot of images over the network. So instead, we shaft the client and they get to pay in the cycles building the graph in their browser. (☞゚∀゚)☞
Lambda Function and the API Gateway
I’m going Camping, not thinking about this.
After Camping
Camping was more a 30km day walk in the Southern Ranges of Tasmania (Moonlight creek). I didn’t feel crash hot as I started. I put this down to not being in the spirit of things as I started walking. I pressed on hoping I’d get more enthusiastic as the day progressed.
As a side note, I’m somewhat a determined (stubborn) person. Only after walking approximately 14km and climbing an elevation of 1000 meters did I stop and think about pushing on and attempting my initial goals. It was at this point I decided to pike on the walk and turn back. The weather was good but also bad. It was sunny, but with 40 to 50km winds that were constantly pushing me about. There was no cover and I thought about risk. The biggest risk I could see is I wasn’t really pumped to be doing the hike. Good spirits when outdoors is everything.
I turned it around and headed out. Got home and slept for 16 hours.
I think I may have had a cold or something. Usually, before I head out on these sorts of trips, I’m really pumped for them. However, it may have just been the location. Moonlight Ridge is a crappy crappy part of the world. Great past hill 1, but everything before that, thumbs down.
Anyway, I’ve been there before, and I’ll go again.
Back to this project.
When you start messing around with Lambda and integrations the Events package is really handy to read. aws/aws-lambda-go-events
Thankfully I had the original POST based Lambda to build most of this logic off. At the point of writing this I have that uploaded and working . It’s got no effective error handling at the moment but that can come in time.
I lost about two, or maybe three hours trying to figure out a small problem with AWS and what eventually turned out to be CloudFront.
I spent a lot of time just refreshing my browser and turnings things on and off again. I’m a little more methodical at work with comms bugs. Usually, it’s just a matter of testing each jump in the network to find the error. If I’d tried the Lambda, then API Gateway externally, I would have clued to the error not being on the Lambda or API Gateway setup. Admittedly, I haven’t done tons of Lambda stuff to be an old hand at it yet. I probably won’t fall into that trap again.
It was late, I blame that for not following a process to solve my problem.
Some interesting things came out of it.
- Caching and Pass-through policies on the API’s CloudFront distribution need to be enabled for query strings. Pretty easy to set up, it’s also pretty easy to ignore.
- Interestingly, you can white list query parameters. Importantly, the order in which you specify them in the white list becomes significant to whomever calls the API. Caches like Varnish (which Fastly use) have built-in helper functions in the cache libraries such as querystort. Querysort does just that and orders query params to increase cache hits. I wonder if AWS has done the math of that and decided against spending the extra compute?
Anyway. It’s done. the API works.
The UI bits
This little side project is great. So many problems, so little forethought.
The most significant problem I have is that I have a service that exposes a tree of data, but interacting with that tree is dependent on you, the user, knowing the identity of a node. (╯°□°)╯︵ ┻━┻.
This is a dumb position to be in.
I could think about building a search but gah! I don’t really want to do that.
Instead, I’m going to do two things.
-
Create a D3 visualization that you can add elements as you click about nodes.
Something like this really awesome demo from D3: Mobile Patent Suits
-
Design and build a different tool that does everything I actually want but with less fuss.
I’m thinking along the lines of clicking a point on a Map of Aus and then finding out what regions exist in that point and what their relations up and down the chain are. I think I can do this pretty easily with the ArcGIS Javascript API, using the FeatureLayer Query function … I think.
But all of that can wait for part 3, once I learn how to use D3.js.